卷积神经网络(CNN)
从 MLP 的归纳偏置不足讲起,理解卷积层(局部连接、参数共享、平移等变)、步长/空洞卷积与特征图尺寸计算、池化、感受野,以及 LeNet/AlexNet/VGG/ResNet 等经典网络与残差连接。
🎯学习目标
- 理解 MLP 的不足与 CNN 的归纳偏置(局部性、平移等变、参数共享);
- 掌握卷积层的五个视角、多通道卷积与参数量计算;
- 掌握步长 stride、填充 padding、空洞卷积及特征图尺寸公式;
- 理解最大/平均/全局池化、1×1 卷积、降采样与上采样;
- 掌握感受野、特征图概念,编码器-解码器与 U-Net;
- 熟悉 LeNet/AlexNet/VGG/GoogLeNet/ResNet 与残差连接。
1从 MLP 到 CNN
MLP 是通用、简洁、易并行的近似器,但缺点明显:
图像具有局部性与平移不变性:相关的事物聚集在一起,相距甚远的可假设相互独立;同样的内容在不同位置应被同样处理。
若假设输出是输入的局部函数,并对每个局部用相同权重(权重共享)计算,就得到了卷积神经网络。
MLP的问题:
- 全连接:每个神经元连所有像素
- 参数太多:1000×1000图像需要10亿参数
- 没有"局部性"假设:不知道图像的局部相关性
CNN的改进:
1. 局部连接:只连局部区域
2. 权重共享:所有位置用同一组权重
3. 平移不变性:同样的内容在不同位置被同样处理
归纳偏置:
- CNN假设图像有"局部性"和"平移不变性"
- 这些假设是对的,所以CNN效果好
- 如果假设不对(比如全局关系很重要),CNN效果就差
参数量对比:
- MLP:1000×1000×1000 = 10亿参数
- CNN(3×3卷积核):3×3×通道数 = 几百个参数
- CNN参数量少几个数量级!
平移等变性:
- 输入平移,输出也平移
- 比如:猫在左边 → 特征在左边
- 猫在右边 → 特征在右边
- 这对图像处理很重要
2卷积层与五个视角 ⭐
卷积层是一种受约束的线性层:其权重矩阵是 Toeplitz(托普利茨)矩阵(每条左上到右下对角线元素相同)。约束带来更少的参数 → 更易学习、更少过拟合,且能应用于任意尺寸输入。
就像用放大镜看照片:
- 放大镜 = 卷积核(3×3 的小窗口)
- 照片 = 输入图像
- 扫描过程 = 卷积核在图像上滑动
每到一个位置:
1. 看看窗口里的像素
2. 和卷积核做匹配
3. 匹配程度 = 输出值
不同的卷积核找不同的特征:
- 边缘检测核 → 找边缘
- 模糊核 → 做模糊
- 锐化核 → 做锐化
卷积层的五个视角
平移等变
输入平移,输出同样平移。
区域块处理
对每个 patch 做处理。
图像滤波
卷积即滤波运算。
参数共享
各位置共用一组权重。
处理可变尺寸
可处理任意大小张量。
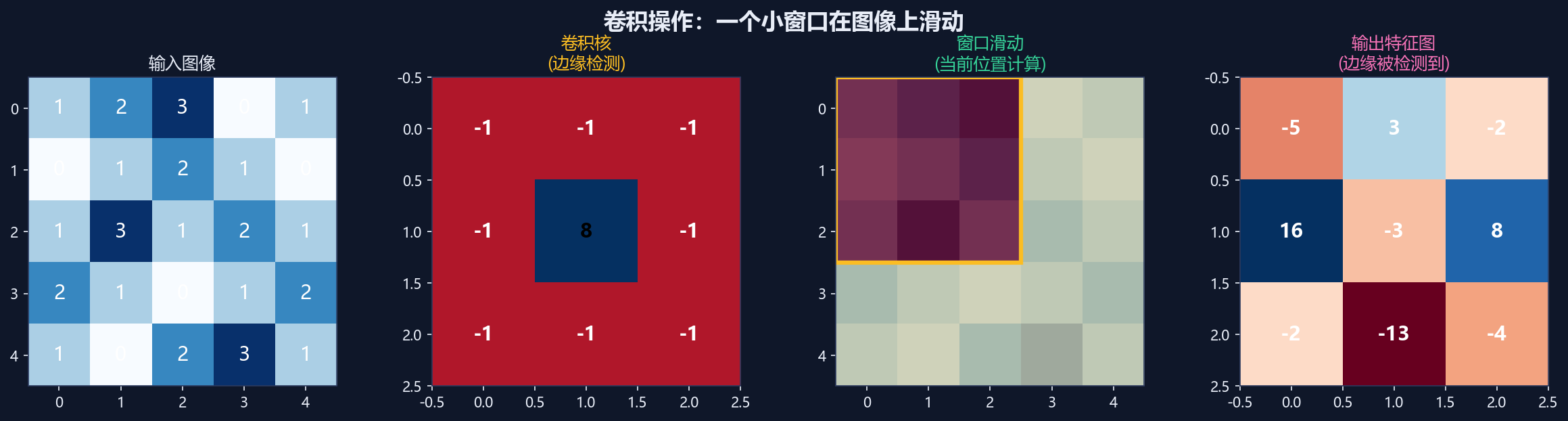
核心意思:
卷积 = 用"特征探测器"扫描图像,提取局部特征
举个例子:
输入图像(5×5):
1 1 1 0 0
0 1 1 1 0
0 0 1 1 1
0 0 0 1 1
0 0 0 0 1
卷积核(3×3,边缘检测):
-1 -1 -1
-1 8 -1
-1 -1 -1
计算过程(在位置(1,1)):
窗口:1 1 1
0 1 1
0 0 1
计算:1×(-1) + 1×(-1) + 1×(-1) +
0×(-1) + 1×8 + 1×(-1) +
0×(-1) + 0×(-1) + 1×(-1)
= -1 + -1 + -1 + 0 + 8 + -1 + 0 + 0 + -1
= 3
不同的卷积核找不同的特征:
卷积核 检测的特征
边缘检测核 找边缘
模糊核 做模糊
锐化核 做锐化
角点检测核 找角点
生活类比:
- 卷积核:像放大镜
- 图像:像照片
- 卷积过程:用放大镜在照片上滑动
- 每到一个位置:看看周围的像素,计算一个新值
为什么CNN有效?
因为图像有"局部性":相关的事物聚集在一起,卷积核正好利用了这个特性。
3多通道卷积与参数量 ⭐
图像处理中卷积常指单通道滤波;但神经网络的卷积层更通用——把多通道输入映射为多通道输出。
- 多通道输入:对 RGB 图像 $x \in \mathbb{R}^{3 \times H \times W}$,用多通道滤波器 $w \in \mathbb{R}^{3 \times K \times K}$,对各输入通道分别滤波再相加,得到单通道输出;
- 多通道输出:用一个滤波器组 $\{w_0, \ldots, w_{C-1}\}$,每个滤波器产生一个输出通道(称为特征图 feature map);
- 通用卷积层:把 $C_{in}$ 通道映射为 $C_{out}$ 通道,滤波器组是张量 $w \in \mathbb{R}^{C_{out} \times C_{in} \times K \times K}$。
每个滤波器参数 $$= C_{in} \times K \times K$$
(加偏置则 $$+1$$)
整层参数量 $$= C_{out} \times (C_{in} \times K \times K + 1)$$例:输入 3 通道、3×3 核,则每个滤波器有 $3 \times 3 \times 3 = 27$ 个参数;滤波器个数 = 输出通道数(题目未给则无法确定)。4步长、填充、空洞卷积与尺寸计算 ⭐
步长卷积(Strided Convolution)
标准卷积保持空间分辨率;步长卷积以步长 $S$ 跳跃扫描,实现下采样 $\mathbb{R}^{H \times W} \to \mathbb{R}^{H/S \times W/S}$。可显著降低算力/内存,但会降低卷积质量("跳跃式扫描"漏细节),DFT 上可见混叠 aliasing 伪影。
输出 $$= \lfloor (W - F + 2P) / S \rfloor + 1$$ $$W$$=输入尺寸 $$F$$=卷积核大小 $$P$$=填充 $$S$$=步长
填充(Padding)
在输入边缘补零(P),可控制输出尺寸(如 same 填充保持尺寸不变)。
空洞卷积(Dilated Convolution)
把卷积核元素在空间上拉开间距(空洞率 d),在不降分辨率、不增参数的前提下指数级扩大感受野。等效核大小:
$$K_{\text{dilated}} = (K - 1) \times d + 1$$
5池化层(Pooling)
池化是一种降采样层,用某种聚合统计量概括一个图像块内的信息:
| 类型 | 聚合方式 | 作用 |
|---|---|---|
| 最大池化 Max | 取窗口最大值 | 对小平移稳定(不管边缘精确位置都有大响应) |
| 平均池化 Avg | 取窗口平均值 | 平滑、降采样 |
| 跨通道池化 | 在特征通道间池化 | 可实现旋转不变性(总有某角度滤波器响应) |
| 全局池化 Global | 对整张特征图池化 | $C \times M \times N$ → 长度 $C$ 的向量,常用于输出端 |
此外还有非线性滤波层:与卷积类似在张量上滑窗、相同独立处理,但执行的是局部窗口的非线性函数(如池化即一种)。
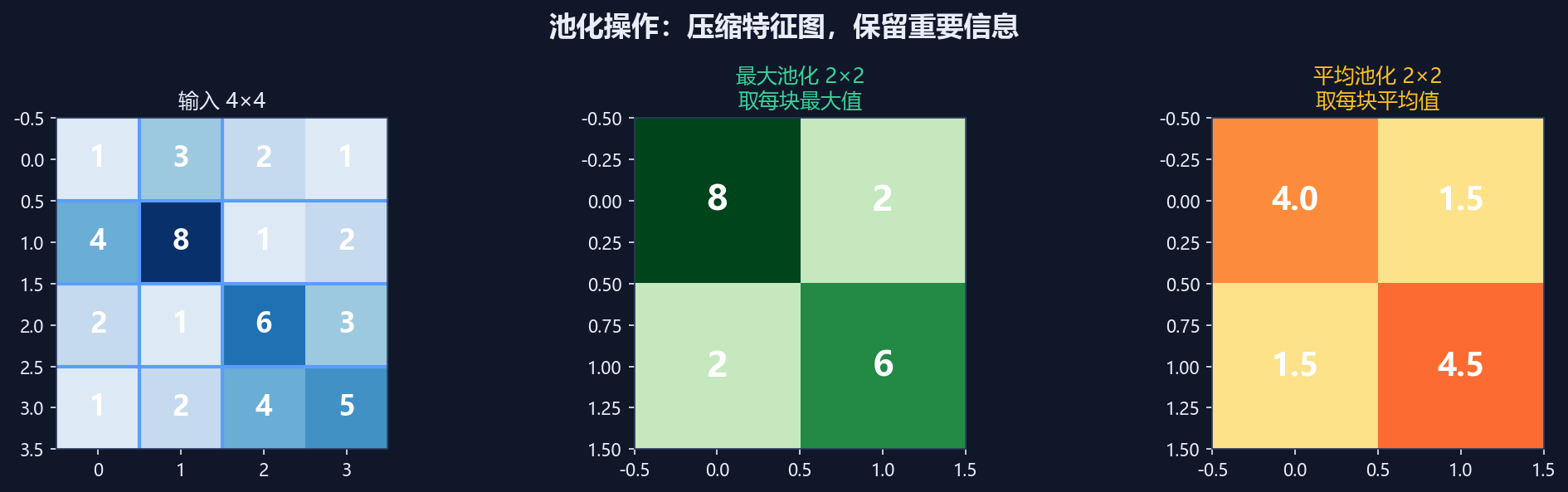
核心意思:
池化 = 缩略图,把大图变小,保留最重要信息
举个例子:
输入特征图(4×4):
1 3 2 1
4 8 1 2
2 1 6 3
1 2 4 5
最大池化(2×2,步长2):
每个2×2区域取最大值:
区域1:[1,3,4,8] → 8
区域2:[2,1,1,2] → 2
区域3:[2,1,1,2] → 2
区域4:[6,3,4,5] → 6
输出:
8 2
2 6
平均池化(2×2,步长2):
每个2×2区域取平均值:
区域1:(1+3+4+8)/4 = 4.0
区域2:(2+1+1+2)/4 = 1.5
区域3:(2+1+1+2)/4 = 1.5
区域4:(6+3+4+5)/4 = 4.5
输出:
4.0 1.5
1.5 4.5
对比:
方法 特点 用途
最大池化 保留最显著特征 分类任务
平均池化 保留整体信息 特征压缩
生活类比:
- 池化就像做缩略图
- 把4×4的图变成2×2的图
- 但保留了最重要的信息
为什么需要池化?
1. 减小特征图尺寸,降低计算量
2. 扩大感受野,看到更大范围
3. 对小平移保持稳定(特征位置不敏感)
61×1 卷积与上下采样
1×1 卷积
- 跨通道信息集成;升维与降维;
- 引入非线性(后接激活函数),让网络更深、学更复杂决策边界;
- 不改变感受野与特征图尺寸,且只增极少参数、计算代价微乎其微。
降采样与上采样
CNN 可构建为分析-合成金字塔:分析时降采样(减空间维度、降算力、扩感受野、提取高级语义),合成时上采样(恢复空间细节)。
| 方向 | 方法 |
|---|---|
| 降采样 | 步长卷积、池化 |
| 上采样 | 反池化 (Unpooling)、插值(最近邻/双线性)、转置卷积(反卷积,先膨胀再卷积) |
7感受野与特征图
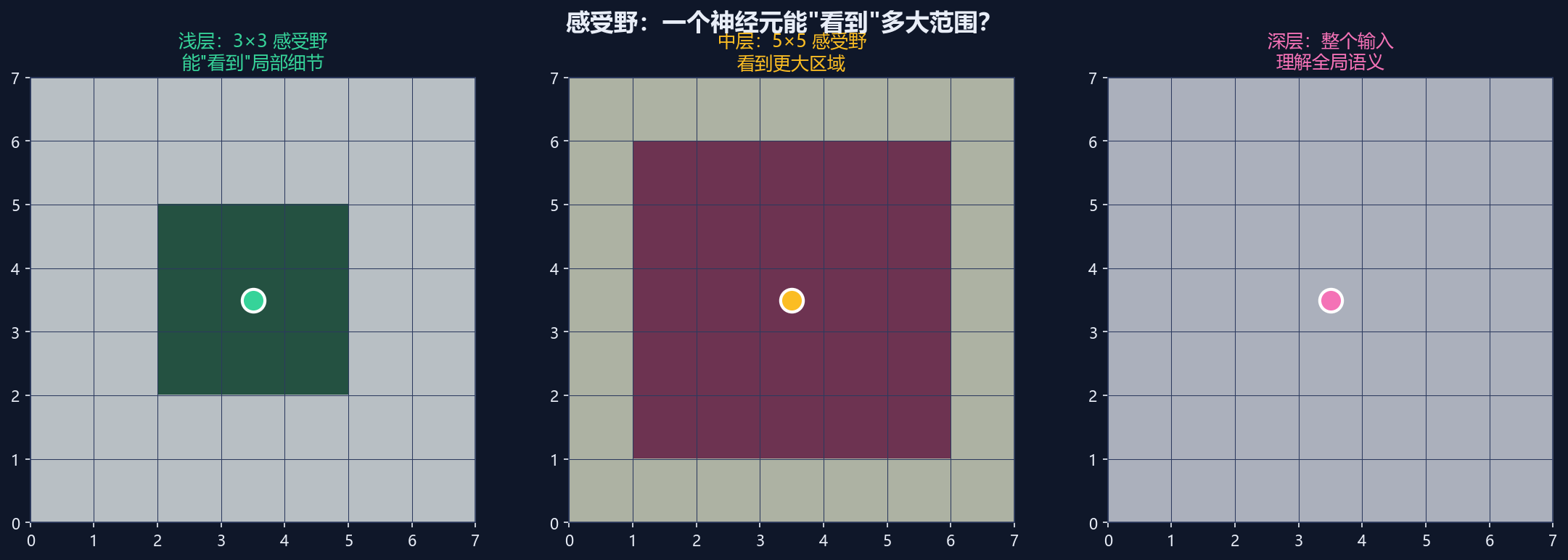
感受野(Receptive Field)
一个神经元的感受野是输入信号中它所敏感的区域。MLP 中每个神经元的感受野是整个输入;CNN 中每个神经元只能"看到"输入的一部分(由卷积核大小决定)。网络越深,感受野越大;常希望最后一层感受野覆盖整张图(如全局平均池化天然覆盖全图)。
特征图(Feature Map)
- 特征图既可指卷积层输出的某个通道,也可指某层所有通道的整体堆叠;
- 对图像是 2D 空间数组;对视频是 3D 时空数组;
- 随网络加深:空间分辨率越来越低,通道数越来越多——浅层敏感于边缘/线条,深层组合成角点、纹理乃至高级语义(信息重组)。
从分类到像素级理解:分类输出单个类别向量(全局池化压成一点);稠密预测(如语义分割)需保留空间位置。降采样太多则语义强但位置模糊,太少则位置准但语义弱(感受野太小)。
感受野的定义:
- 一个神经元能"看到"的输入区域
- 就像你的"视野"有多大
浅层感受野:
- 只能看到一小块区域
- 提取局部特征(边缘、纹理)
深层感受野:
- 能看到更大区域
- 提取全局特征(物体、场景)
如何扩大感受野?
1. 增加卷积核大小(比如从3×3到5×5)
2. 堆叠更多层(每层扩大一点)
3. 使用池化(尺寸减半,感受野加倍)
4. 使用空洞卷积(不增加参数)
空洞卷积:
- 卷积核元素之间有间隔
- 等效核大小 = (K-1)×d + 1
- d是空洞率,K是原始核大小
- 例子:3×3卷积核,空洞率2 → 等效5×5
特征图的变化:
- 浅层:尺寸大,通道少,细节多
- 深层:尺寸小,通道多,语义多
- 就像"金字塔":越往上越小,但信息越抽象
核心意思:
特征图 = 卷积层输出的"特征地图",每个通道检测一种特征
举个例子:
输入图像(猫的照片)经过卷积层后:
通道1(边缘检测):
- 检测到猫的轮廓
- 值大的地方 = 有边缘
通道2(纹理检测):
- 检测到猫的毛发纹理
- 值大的地方 = 有纹理
通道3(颜色检测):
- 检测到猫的颜色
- 值大的地方 = 有特定颜色
...共64个通道,每个检测不同特征
特征图的变化规律:
浅层(第1层):
- 尺寸大(和原图差不多)
- 通道少(64个)
- 特征简单(边缘、颜色)
深层(第10层):
- 尺寸小(缩小很多)
- 通道多(512个)
- 特征复杂(眼睛、耳朵、整体形状)
可视化深层特征图:
用PCA把512维降到3维,映射到RGB:
- 同色区域 = 网络认为相似的特征
- 比如"天空"都是蓝色,"建筑"都是红色
生活类比:
- 特征图:像不同滤镜下的照片
- 每个通道:像一种特殊的眼镜
- 浅层特征:像看到线条和颜色
- 深层特征:像看到物体和场景
8编码器-解码器与 U-Net
编码器以图像为输入逐层降采样到低维特征图;解码器以低维特征为输入逐层上采样到图像输出。二者结合即编码器-解码器架构,强制信号通过一个信息瓶颈——迫使网络抽象,同时降采样省内存算力。
核心意思:
编码器 = 压缩信息,解码器 = 恢复信息,像"压缩-解压缩"过程
举个例子:
图像分割任务(给每个像素分类):
编码器(下采样):
输入:256×256×3(原图)
→ 卷积+池化 → 128×128×64
→ 卷积+池化 → 64×64×128
→ 卷积+池化 → 32×32×256
→ 卷积+池化 → 16×16×512(瓶颈)
作用:提取特征,压缩信息
问题:空间信息丢失了!
解码器(上采样):
输入:16×16×512(瓶颈)
→ 上采样+卷积 → 32×32×256
→ 上采样+卷积 → 64×64×128
→ 上采样+卷积 → 128×128×64
→ 上采样+卷积 → 256×256×类别数
作用:恢复空间信息,输出分割结果
U-Net的跳跃连接:
编码器的特征 → 拼接 → 解码器 好处:保留空间细节,分割更精准
生活类比:
- 编码器:像把文章压缩成摘要
- 解码器:像把摘要扩写回文章
- 跳跃连接:像写摘要时保留原文关键段落
为什么需要编码器-解码器?
1. 减少计算量(压缩后处理更快) 2. 扩大感受野(看到更大范围) 3. 提取语义特征(理解图像内容)
9经典网络与 ResNet ⭐
ImageNet 数据集:约 100 万张带标签图像、1000 个类别,是经典网络的试金石(ILSVRC 竞赛)。
| 网络 | 层数 | 特点 |
|---|---|---|
| LeNet | ~7 层 | 最早的卷积网络(手写数字) |
| AlexNet | 8 层 | 2012 ImageNet 突破,ReLU + Dropout |
| VGG | 16 层 | 统一用 $3 \times 3$ 小卷积堆叠 |
| GoogLeNet | 22 层 | Inception 模块 |
| ResNet | 152 层 | 2015 ILSVRC 冠军,错误率 3.57%,引入残差连接 |
问题:网络太深会"退化"
- 深层网络效果反而不如浅层
- 因为信息经过太多层会"丢失"
残差连接的做法:
- 不直接学输出 F(x)
- 而是学"和输入的差" F(x) - x
- 最终输出 = x + F(x)
就像:
- 你要从 A 走到 B
- 不是走一条很长的路
- 而是"从 A 出发,走一小段修正,回到 A + 修正"
好处:
- 梯度可以直接传回去(不会消失)
- 网络可以很深(100+层)而不会退化
问题:深度网络的"退化"现象
- 网络越深,效果反而越差
- 不是过拟合(训练集上也差)
- 是因为梯度消失/爆炸
残差连接的做法:
- 不直接学输出 F(x)
- 而是学"和输入的差" F(x) - x
- 最终输出 = x + F(x)
类比:
- 你要从A走到B
- 不是走一条很长的路
- 而是"A + 修正量"
- 修正量很小,容易学
好处:
1. 梯度可以直接传回去(不会消失)
2. 网络可以很深(100+层)
3. 至少不会比浅层差(最坏情况F(x)=0)
ResNet的贡献:
- 让网络可以训练到100+层
- 在ImageNet上取得突破
- 成为深度学习的里程碑
残差块的结构:
- 输入 → 卷积 → BN → ReLU → 卷积 → BN → +输入 → ReLU
- 跳跃连接绕过两层卷积
- 梯度可以通过跳跃连接直接传回
核心意思:
残差连接 = "抄近道",让梯度可以直接传回去,解决深层网络的退化问题
举个例子:
传统网络(无残差):
输入x → 层1 → 层2 → ... → 层n → 输出F(x)
问题:层数太多,梯度会消失,网络退化
残差网络:
输入x → 层1 → 层2 → ... → 层n → F(x)
↓ ↓
└──────────────────────────────→ + → 输出 = x + F(x)
跳跃连接:x 直接加到输出上
好处:
1. 梯度可以通过跳跃连接直接传回去(不会消失)
2. 网络可以很深(100+层)
3. 至少不会比浅层差(最坏情况F(x)=0,输出=x)
数值示例:
输入x = 100
传统网络:F(x) = 0.01(梯度消失,输出很小)
残差网络:x + F(x) = 100 + 0.01 = 100.01(输出接近输入)
生活类比:
- 传统网络:像走一条很长的路,可能迷路
- 残差网络:像有"高速公路",可以直接到达目的地
ResNet的贡献:
- 让网络可以训练到100+层
- 在ImageNet上取得突破
- 成为深度学习的里程碑
⭐重点例题
输出 $$= (W - F + 2P)/S + 1$$
$$= (32 - 5 + 2 \times 2)/1 + 1$$
$$= 31/1 + 1 = 32$$
结论:输出为 $32 \times 32$(same 填充,尺寸不变)。
每个滤波器 $$= C_{in} \times K \times K = 3 \times 3 \times 3 = 27$$($$+1$$ 偏置 $$= 28$$)
整层 $$= C_{out} \times (C_{in} \cdot K \cdot K + 1) = 64 \times 28 = 1792$$
对应课件例题:输入 3 通道、3×3 核,每个滤波器参数 $= 3 \times 3 \times 3 = $27(答案 b);滤波器个数 = 输出通道数,题目未给则无法确定。
② 残差连接作用:让网络学习残差 $h(x)-x$ 而非直接学 $h(x)$,形成嵌套函数类,缓解深层退化与梯度问题,使极深网络(152 层)可训练。
🎯自测(点击展开)
从全连接层如何一步步得到卷积层?
卷积层为什么参数比全连接少?
写出卷积输出尺寸公式。
最大池化为什么能带来平移稳定性?
1×1 卷积有哪些用途?
残差连接如何表达目标函数?
📝强化题库
选择题点选即时判分;填空题输入后"检查"或"显示答案"。