Transformer 网络
从 CNN 的局部性局限出发,理解注意力机制、词元(Token)、QKV 缩放点积注意力、自注意力与多头注意力,以及位置编码、Encoder-Decoder 架构和视觉 Transformer(ViT)。
🎯学习目标
- 理解 CNN 处理全局信息的局限,以及 Transformer 的引入动机;
- 掌握注意力机制、词元(Token)化与词元序列;
- 理解 Query-Key-Value 与缩放点积自注意力的计算;
- 掌握多头自注意力、Transformer Block(FFN + LayerNorm + 残差);
- 理解置换等变性与位置编码、因果(掩码)注意力;
- 比较 CNN 与 Transformer,了解 ViT 与大语言模型。
1CNN 的局限
CNN 的核心是局部性思想:图像不同局部区域可被安全地独立处理。但其局限是不擅长处理全局信息。
CNN 处理全局信息的两种方式:
- 方式1:增大卷积核尺寸;
- 方式2:堆叠更多层,扩大深层神经元的感受野。
2MLP / CNN / RNN 对比
| 架构 | 优点 | 缺点 |
|---|---|---|
| 全连接 MLP | 可全局信息传递 | 参数量大;无法处理变长;无平移/旋转不变性 |
| 卷积 CNN | 参数少(权值共享);平移不变;可并行 | 长程依赖建模弱(需堆叠层) |
| 循环 RNN | 处理任意长度序列;有时序记忆 | 并行化困难;长程依赖建模弱 |
3注意力机制
注意力是一种高效处理全局信息的策略:只聚焦于信号中对当前任务最显著的部分,而不是一次性接收整个场景。
在神经网络中,第 l 层的一组神经元会关注第 l−1 层的一组神经元,以决定如何响应。例如若"要求"报告图中任意汽车的颜色,它们就应把注意力导向上一层中代表汽车颜色的神经元。
4词元(Token)与词元化
词元(Token)是神经元的另一种组合形式,可视为封装的信息组,用一个列向量 $t \in \mathbb{R}^{d \times 1}$ 表示(也叫代码向量)。Transformer 运行在词元阵列之上(矩阵 $X$ 是词元的一维阵列)。
数据词元化
- 用一个 Token 代表图像中的每一个图像块(patch),整幅图对应一个词元阵列;
- 直接向量化:不涉及学习,只是数据重排(如 16×16 像素 RGB 拉成 768 维向量 x);
- 低维投影:引入可学习的嵌入矩阵 $W$,$z = W \cdot x$。
Transformer 对词元有两项核心操作:线性组合与逐点非线性变换(主流用 MLP,含可学习参数)。
什么是词元?
- 把输入切成小块,每块叫一个词元
- 就像把文章切成"词"或"句子"
在文本中:
- "我喜欢深度学习" → ["我", "喜欢", "深度", "学习"]
- 每个词就是一个词元
在图像中:
- 把图像切成16×16的小块
- 每个小块就是一个词元
- 每个词元是一个向量(比如768维)
词元化的好处:
- 统一处理不同类型的输入
- 文本、图像、音频都可以切成词元
- Transformer只需要处理词元序列
词元 vs 像素:
- 像素:很小,信息量少
- 词元:更大,包含更多语义信息
- 例子:一个16×16的词元包含256个像素的信息
5Query-Key-Value 注意力 ⭐
注意力层是一种特殊的词元线性组合——它是一个权重由数据动态决定的全连接层(也叫"动态池化":加权平均,权重随输入动态确定)。
- 权重矩阵 A 是输入数据的函数,告诉我们应关注(赋予较高权重)哪些词元;
- A 通常仅含非负值;A 实际确定了词元的组合权重。
QKV 三角色(点击翻转)
Query
查询 Q=WqXKey
键 K=WkXValue
值 V=WvXQKV 与缩放点积注意力
三个可学习映射矩阵把词元投影为 Query(查询)、Key(键)、Value(值)。Q 与 K 的匹配相似度决定权重,再对 V 加权求和:
$$Q = W_q \cdot X , K = W_k \cdot X , V = W_v \cdot X$$
注意力权重 $$A = \text{softmax}( Q \cdot K^T / \sqrt{d_k} )$$ ← 缩放点积(除以 $$\sqrt{d_k}$$)
输出 $$= A \cdot V$$ ← 对 Value 加权求和
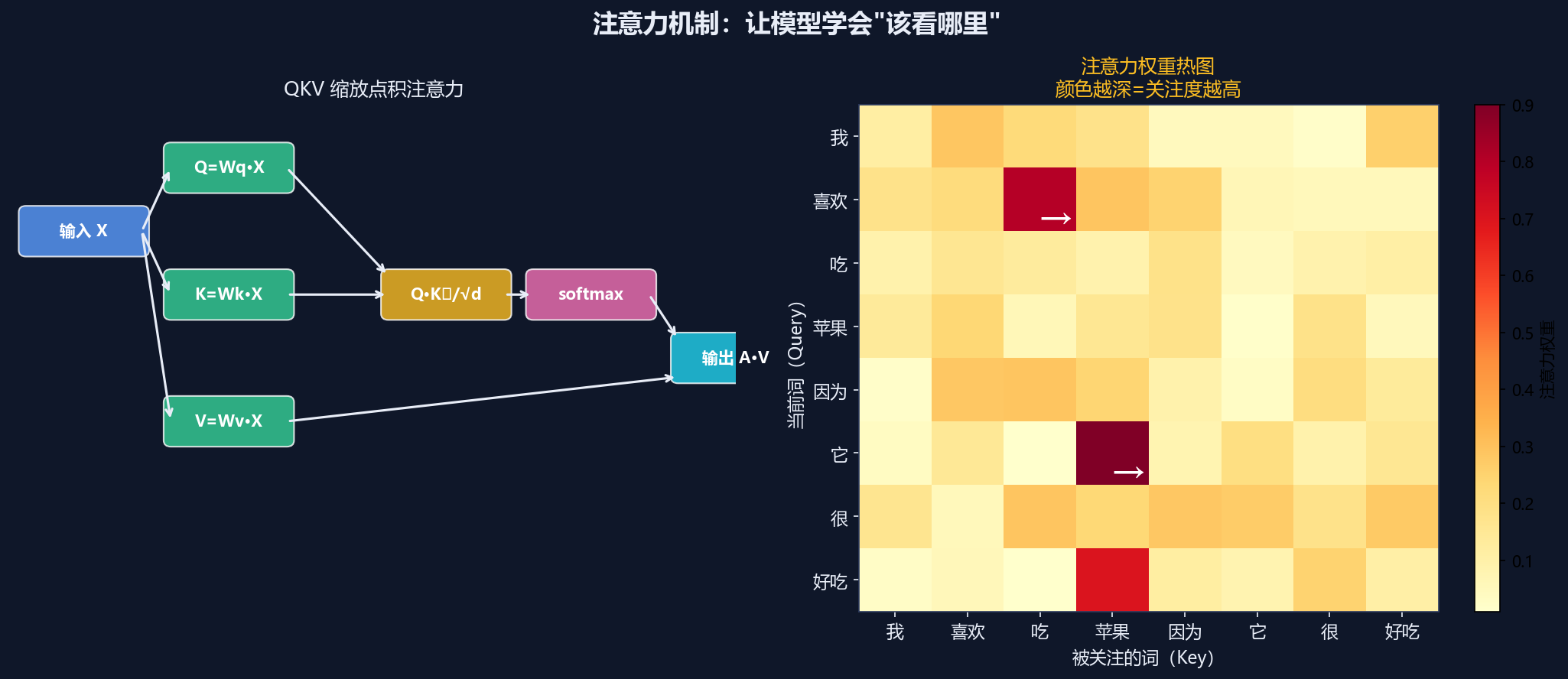
核心意思:
QKV = 图书馆找书:Query是需求,Key是标签,Value是内容
举个例子:
句子:"猫坐在垫子上因为它很软"
计算"它"的注意力:
Query("它"想找什么):
"我是一个代词,我需要找我的先行词"
Key(每个词的标签):
"猫":我是一个名词,可能是动物
"坐":我是一个动词
"垫子":我是一个名词,可能是物品
"软":我是一个形容词
Value(每个词的内容):
"猫":[0.2, 0.8, 0.1, ...]
"坐":[0.1, 0.1, 0.9, ...]
"垫子":[0.3, 0.2, 0.5, ...]
"软":[0.4, 0.1, 0.3, ...]
计算相似度(Q·K):
"猫":0.8(很相似,都是名词)
"坐":0.2(不太相似)
"垫子":0.5(有点相似)
"软":0.3(不太相似)
Softmax后得到权重:
"猫":0.6
"垫子":0.2
"软":0.1
"坐":0.1
最终输出 = 加权求和:
0.6×"猫" + 0.2×"垫子" + 0.1×"软" + 0.1×"坐"
结果:"它"的表示包含了"猫"的信息(因为权重最大)
生活类比:
就像在图书馆找书:
- 你说:"我要找关于深度学习的书"(Query)
- 每本书的标签是:机器学习、烹饪、数学...(Key)
- 你根据标签选书,相关度高的多看几眼(权重)
- 最后你带走的书 = 相关度高的书的内容(Value)
6自注意力(Self-Attention)
自注意力:Q、K、V 都来自同一组输入词元,让每个词元根据其他词元的上下文来优化自身表示。
- 词元 t₂ 关注代表"黑斑羚"其他部位的词元,借助上下文把 t₂ 优化为更抽象、捕捉"黑斑羚"标签的向量;
- 减少被关注图像块之间不共享的噪声,放大它们的共性。
核心意思:
自注意力 = 每个词都能看到所有词,根据相关性调整自己的表示
举个例子:
句子:"猫坐在垫子上因为它很软" 传统方法(CNN): - 只能看到局部(比如3个词的窗口) - "它"可能只能看到"垫子上" - 不知道"它"指的是"猫" 自注意力: - 每个词都能看到所有词 - "它"可以看到"猫"、"坐"、"垫子"、"软" - 根据相似度,"它"主要关注"猫" - 所以"它"的表示包含了"猫"的信息 动态感受野: - Query变了,关注的区域就变了 - 如果Query是"软",可能主要关注"垫子" - 如果Query是"它",可能主要关注"猫" 打破空间限制: - CNN只能看邻近像素 - 自注意力可以看任何位置 - 只要特征匹配,就能赋高权重 - "天涯若比邻"
生活类比:
- CNN:像通过一个小孔看世界,只能看到局部
- 自注意力:像有全局视野,能看到所有东西
7多头自注意力(Multi-Head Self-Attention)
映射矩阵 W_q、W_k、W_v 定义了一种"相似度概念"。单个自注意力层只能用一种方式衡量相似度。Transformer 使用多头自注意力:并行运行 k 个注意力层(头),各自学习不同的相似度/关注模式,再拼接。
核心意思:
多头注意力 = 并行运行多个注意力,每个关注不同的"相似度概念"
举个例子:
句子:"猫坐在垫子上因为它很软"
单头注意力:
- 只能用一种方式衡量相似度
- 比如只看词性(名词关注名词)
- "它"可能关注"猫"和"垫子"
多头注意力(假设4个头):
- 头1:关注词性(名词→名词)
"它" → "猫"(0.6), "垫子"(0.3)
- 头2:关注语义(代词→先行词)
"它" → "猫"(0.7), "垫子"(0.2)
- 头3:关注位置(距离近的词)
"它" → "垫子"(0.5), "软"(0.3)
- 头4:关注语法关系(主语→宾语)
"它" → "猫"(0.8)
最终:把4个头的结果拼接起来
"它"的表示 = [头1结果, 头2结果, 头3结果, 头4结果]
为什么需要多头?
因为"相似度"有很多维度: - 词性相似 - 语义相似 - 位置相近 - 语法相关 单头只能学一种,多头能学多种!
生活类比:
- 单头:像一个人从一个角度看问题
- 多头:像多个人从不同角度看问题,综合意见
8完整 Transformer 架构
一个 Transformer Block 由以下部分组成:
- 注意力层:跨词元混合信息;
- 前馈层(Feedforward / MLP):N 个逐位置网络,每个位置独立处理;同一层各位置权重相同,但不同层参数不同;
- 层归一化(Layer Norm)与残差连接。
整体常用 Encoder-Decoder 结构:Encoder 编码输入序列,Decoder 结合 Encoder 输出与已生成内容产生输出。
9置换等变性与位置编码 / 掩码注意力
置换等变(Permutation Equivariance)
纯注意力对词元的顺序不敏感(置换输入则输出同样置换)——这意味着它本身丢失了空间/顺序信息。
位置编码(Positional Encoding)
把一个表示位置的编码拼接到每个词元上,恢复位置信息。常用位置的周期性(正弦/余弦)表示:把坐标编码为一组不同频率正弦波在该位置的取值组成的向量。
$$\sin(x)$$ → 波长极短、频率极高 $$\sin(x/B^i)$$ → 波长极长、频率很低 (多个频率组合可唯一表示每个位置)
因果(掩码)自注意力 Causal Self-Attention
用于语言模型/自回归生成:每个位置只能看到当前及之前的输入,不能看未来。
问题:
- 自注意力是"无序"的
- 不知道词元的先后顺序
- "我吃饭"和"饭吃我"是一样的
解决:位置编码
- 给每个词元加上"位置信息"
- 就像给每个词贴上"序号标签"
位置编码的方式:
- 正弦余弦函数:用不同频率的波
- 可学习位置编码:让模型自己学
- 相对位置编码:只关心相对距离
正弦余弦编码:
- 每个位置有不同的编码
- 相近位置的编码相似
- 远离位置的编码不同
- 就像给每个位置一个"指纹"
为什么用正弦余弦?
- 可以表示任意长度的序列
- 相对位置可以通过线性变换得到
- 计算高效
核心意思:
位置编码 = 给每个词元加上"位置信息",告诉模型词序
举个例子:
句子:"我 爱 深度 学习"
没有位置编码:
"我" = [0.2, 0.8, 0.1, ...]
"爱" = [0.3, 0.5, 0.7, ...]
"深度" = [0.1, 0.9, 0.2, ...]
"学习" = [0.4, 0.6, 0.3, ...]
问题:"我爱学习"和"学习爱我"的表示一样!
有位置编码:
位置0的编码 = [sin(0), cos(0), sin(0), ...] = [0, 1, 0, ...]
位置1的编码 = [sin(1), cos(1), sin(1), ...] = [0.84, 0.54, 0.84, ...]
位置2的编码 = [sin(2), cos(2), sin(2), ...] = [0.91, -0.42, 0.91, ...]
位置3的编码 = [sin(3), cos(3), sin(3), ...] = [0.14, -0.99, 0.14, ...]
"我" = [0.2, 0.8, 0.1, ...] + [0, 1, 0, ...] = [0.2, 1.8, 0.1, ...]
"爱" = [0.3, 0.5, 0.7, ...] + [0.84, 0.54, 0.84, ...] = [1.14, 1.04, 1.54, ...]
现在:"我爱学习"和"学习爱我"的表示不同了!
为什么用正弦余弦?
- 不同位置的编码不同 - 相近位置的编码相似 - 可以表示任意长度的序列 - 计算高效
生活类比:
- 位置编码:像给每个座位贴上号码牌
- 没有号码牌:不知道谁坐哪里
- 有号码牌:知道每个人的座位
10CNN 与 Transformer 对比 · ViT
相同点
- 都做 Token 化(可写成卷积核大小与步长都等于 K 的卷积层);
- 都有 QKV / 1×1 卷积式投影(矩阵相乘 AB 可理解为 B 作为 1×1 卷积核对 A 的卷积);
- 都有逐 Token 的 MLP(线性层本质是 1×1 卷积 + 逐点非线性);
- 都用归一化、残差连接。
不同点
| 对比 | CNN | Transformer |
|---|---|---|
| 核心算子 | K×K 滤波器(相邻区域一起处理) | 尺寸为 1 的卷积 + 位置编码 + 注意力 |
| 感受野 | 固定形状、局部 | 注意力做全局操作,无视空间距离 |
| 空间信息 | 天然保留 | 靠位置编码补充(大卷积核会破坏置换不变性) |
Transformer 因上下文很长(1024 甚至 4096 词元),在条件生成、情感分类、问答、文本摘要等 NLP 任务上非常强大(许多任务可被建模为词预测,自监督并行训练)。
⭐重点例题
① 由输入 $$X$$ 投影得到 $$Q=W_q X, K=W_k X, V=W_v X$$
② 计算相似度分数 $$S = Q \cdot K^T / \sqrt{d_k}$$ (缩放)
③ 归一化为权重 $$A = \text{softmax}(S)$$ (每行和为1,非负)
④ 加权求和输出 $$\text{Output} = A \cdot V$$
关键点:权重 $A$ 由数据动态决定;除以 $\sqrt{d_k}$ 防止点积过大导致 softmax 饱和、梯度消失。
🎯自测(点击展开)
CNN 在处理全局信息上的主要局限是什么?
注意力层和普通全连接层的关键区别?
QKV 各自的作用是什么?
缩放点积为什么要除以 √dₖ?
多头注意力相比单头有什么好处?
因果(掩码)注意力如何屏蔽未来?
📝强化题库
选择题点选即时判分;填空题输入后"检查"或"显示答案"。