回顾:神经网络
从神经元、感知机到多层感知机(MLP);激活函数、前向传播、损失函数、反向传播(BP)与梯度下降,以及归一化与过拟合等深度学习基石。
🎯学习目标
- 理解机器学习中的数据、先验与假设,掌握经验风险与期望风险的关系;
- 掌握神经元、感知机与多层感知机(MLP)的结构;
- 熟悉 Sigmoid / Tanh / ReLU 等激活函数及其优缺点;
- 理解前向传播、损失函数(交叉熵)与反向传播(BP)算法;
- 掌握梯度下降、批大小(batch)、学习率,以及过拟合与正则化、归一化层。
1机器学习基础:数据、先验与假设
机器学习的目标是从数据中、借助先验(priors),在一族假设(hypotheses)中找到最能解释数据的模型。深度网络就是其中一类高度灵活的假设族。
蒙特卡洛(Monte Carlo)估计期望
很多目标都写成期望 $\mathbb{E}_{x \sim p}[f(X)]$。无法解析积分时,用采样平均近似:
1. 从分布 $$p(x)$$ 抽取 $$N$$ 个样本 $$x_1, \ldots, x_N$$
2. 计算 $$\hat{f} = \frac{1}{N} \sum f(x_i)$$
3. 返回 $$\hat{f}$$ 作为 $$\mathbb{E}[f(X)]$$ 的近似
传统编程:
- 人写规则,机器执行
- 例子:if 温度 > 37.5 then 发烧
机器学习:
- 人给数据,机器自己学规则
- 例子:给1000张X光片,机器学会判断是否有肺炎
三个关键概念:
- 数据:用来学习的样本(比如X光片)
- 模型:学习到的规律(比如神经网络)
- 损失:预测和真实的差距(越小越好)
训练过程:
1. 给模型看数据
2. 模型做出预测
3. 计算预测和真实的差距(损失)
4. 调整模型参数,让损失变小
5. 重复直到损失足够小
过拟合 vs 欠拟合:
- 过拟合:模型把训练数据"背下来"了,新数据不行
- 欠拟合:模型没学到规律,训练数据都预测不准
- 好模型:既学到规律,又能泛化到新数据
2神经元与感知机
神经元就像一个决策器,先算加权总分,再用激活函数决定"要不要激活"。具体来说,一个人工神经元先对输入做线性加权求和(含偏置 b),再经过一个非线性激活函数得到输出:
$$z = w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + b$$ (线性) $$a = \sigma(z)$$ (非线性激活)
只含一个神经元、激活为阶跃函数的模型即感知机(Perceptron),只能解决线性可分问题(无法表示异或 XOR)。把许多神经元堆叠成层,就得到深度网络。
核心意思:
神经元 = 一个决策器,先算加权总分,再用激活函数决定"要不要激活"
举个例子:
一个神经元有3个输入:
输入:x1=考试成绩, x2=出勤率, x3=作业完成度
权重:w1=0.5, w2=0.3, w3=0.2
偏置:b=-0.5
计算过程:
z = w1×x1 + w2×x2 + w3×x3 + b
z = 0.5×80 + 0.3×90 + 0.2×100 + (-0.5)
z = 40 + 27 + 20 - 0.5 = 86.5
激活函数(Sigmoid):
a = 1 / (1 + e^(-z)) = 1 / (1 + e^(-86.5)) ≈ 1
结果:神经元"激活"了(输出接近1)
生活类比:
就像面试评分:
- 面试官看多个维度(成绩、出勤、作业)
- 每个维度有不同权重
- 最后算总分,决定是否通过
为什么需要激活函数?
因为如果没有激活函数,多层网络和一层效果一样(线性函数的组合还是线性函数)。
3激活函数 ⭐(核心考点)
非线性激活是深度网络表达力的来源——没有它,多层线性层等价于单层线性层。点击卡片翻转查看要点:
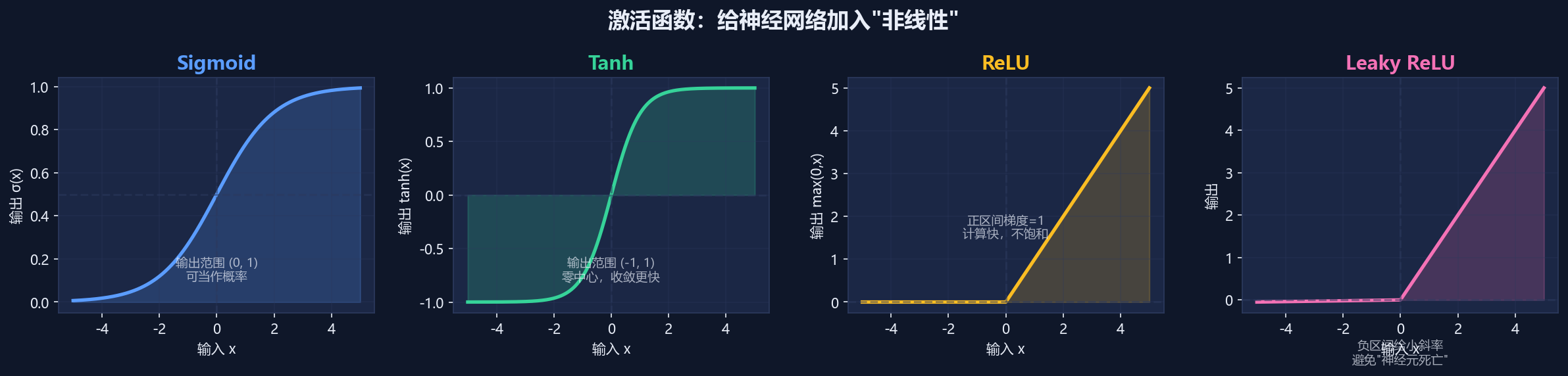
Sigmoid
σ(x)=1/(1+e⁻ˣ)Tanh
tanh(x)ReLU
max(0,x)Leaky ReLU
max(0.01x,x)为什么要激活函数?
- 如果没有激活函数,多层网络和一层效果一样
- 因为线性函数的组合还是线性函数
- 激活函数加入"非线性",让网络能学复杂规律
四种激活函数对比:
Sigmoid:
- 输出范围:(0, 1)
- 特点:可以当概率用
- 缺点:两端太平(梯度消失)
- 类比:把任何数"压缩"到0-1之间
Tanh:
- 输出范围:(-1, 1)
- 特点:零中心,收敛更快
- 缺点:两端也会梯度消失
- 类比:Sigmoid的"升级版"
ReLU:
- 输出:max(0, x)
- 特点:正区间梯度恒为1,计算快
- 缺点:负区间梯度为0(神经元可能"死亡")
- 类比:只让正信号通过
Leaky ReLU:
- 输出:max(0.01x, x)
- 特点:负区间给一个小斜率
- 优点:避免神经元"死亡"
- 类比:ReLU的"改良版"
选择建议:
- 隐藏层:ReLU(默认选择)
- 输出层(分类):Sigmoid(二分类)或Softmax(多分类)
- 输出层(回归):线性激活(不加激活函数)
核心意思:
激活函数 = 给神经网络加入"非线性",让它能学复杂规律
Sigmoid函数:σ(x) = 1/(1+e^(-x))
输入输出对应:
输入x 输出σ(x) 含义
-5 0.007 接近0(不激活)
-2 0.119 较小
0 0.5 一半
2 0.881 较大
5 0.993 接近1(完全激活)
特点:
- 输出范围:(0, 1)
- 可以当概率用
- 两端太平(梯度消失)
ReLU函数:f(x) = max(0, x)
输入输出对应:
输入x 输出f(x) 含义
-5 0 负数变0
-2 0 负数变0
0 0 边界
2 2 正数不变
5 5 正数不变
特点:
- 正区间梯度恒为1(不会梯度消失)
- 计算非常快(只需比较和取最大值)
- 负区间梯度为0(神经元可能"死亡")
为什么需要非线性?
如果没有激活函数:
两层网络:y = W2(W1x + b1) + b2 = W2W1x + W2b1 + b2
这还是线性函数!和一层没区别!
有了激活函数:
两层网络:y = W2σ(W1x + b1) + b2
这是非线性函数,能学更复杂的规律!
生活类比:
- 线性函数:像直线,只能拟合直线关系
- 非线性函数:像曲线,能拟合任意复杂关系
4前向传播与多层感知机(MLP)
MLP 由输入层、若干隐藏层、输出层组成:每一层做一次线性变换 + 非线性激活,逐层把数据映射到下一层表示。
第 $$l$$ 层: $$a^{(l)} = \sigma( W^{(l)} a^{(l-1)} + b^{(l)} )$$
输入: $$a^{(0)} = x$$
输出: $$\hat{y} = \text{softmax}( a^{(L)} )$$
就像工厂流水线:
原料 → 加工1 → 加工2 → 加工3 → 成品
神经网络:
输入 → 层1处理 → 层2处理 → 层3处理 → 输出
每一层做的事:
1. 线性变换(乘以权重 + 加偏置)→ 像"调配比例"
2. 激活函数(加入非线性)→ 像"开关"
为什么要非线性?
- 如果只有线性变换,多层和一层效果一样
- 加入非线性,才能学到复杂规律
核心意思:
前向传播 = 流水线加工,数据从输入层流向输出层
举个例子:
一个3层网络处理图像:
输入层(784个神经元):
输入:28×28=784个像素值
作用:接收原始数据
隐藏层1(128个神经元):
输入:784个值
计算:z1 = W1 × x + b1
输出:a1 = ReLU(z1)
作用:提取低级特征(边缘、纹理)
隐藏层2(64个神经元):
输入:128个值
计算:z2 = W2 × a1 + b2
输出:a2 = ReLU(z2)
作用:提取高级特征(形状、物体)
输出层(10个神经元):
输入:64个值
计算:z3 = W3 × a2 + b3
输出:y = Softmax(z3)
作用:输出10个类别的概率
生活类比:
就像工厂流水线:
- 原料 → 加工1 → 加工2 → 加工3 → 成品
- 每一层都在"加工"数据
- 越深层提取的特征越抽象
5损失函数:经验风险近似期望风险
真实分布 $p(x,y)$ 未知,我们用 i.i.d. 采样得到训练集 $\{(x_n,y_n)\}$。理论目标是最小化期望风险 $\mathbb{E}_{p(x,y)}[\mathcal{L}(\hat{y},y)]$,实践中只能最小化经验风险:
$$\mathcal{L} = \frac{1}{N} \sum_n \mathcal{L}(\hat{y}(x_n), y_n) \leftarrow$$ 经验风险(训练集平均损失)
分类常用交叉熵损失:网络输出各类别概率,取真实类别的 $-\log(\text{prob})$ 作为损失。预测越准、该项越接近 0。
| 损失 | 用途 | 说明 |
|---|---|---|
| 交叉熵 (Cross-Entropy) | 分类 | $-\sum y \cdot \log(\hat{y})$,配合 softmax |
| 均方误差 (MSE) | 回归 | $(\hat{y}-y)^2$ 的平均 |
损失函数告诉你:
- 预测和真实差多少
- 差距越大,损失越大
- 目标是最小化损失
常见损失函数:
均方误差(MSE):
- 公式:(预测 - 真实)² 的平均
- 用途:回归问题(预测连续值)
- 类比:像"标准差",衡量预测的"波动"
交叉熵(Cross-Entropy):
- 公式:-Σ 真实 × log(预测)
- 用途:分类问题(预测类别)
- 类比:衡量两个分布的"距离"
为什么分类用交叉熵?
- MSE在分类问题上训练慢
- 交叉熵梯度更大,训练更快
- 交叉熵更符合"概率"的直觉
经验风险 vs 期望风险:
- 经验风险:训练集上的平均损失
- 期望风险:所有数据上的平均损失(未知)
- 目标:让期望风险最小
- 方法:用经验风险近似期望风险
I.I.D.假设:
- 训练数据独立同分布
- 意味着每个样本都是"公平"的
- 如果违反,模型可能学歪
6反向传播与梯度下降 ⭐
训练一个深度网络分类器的流程,本质是用梯度下降反复迭代:
Forward: 逐层计算激活值 $$a^{(l)}$$,最终得到损失 $$\mathcal{L}$$
Backward: 由 $$\mathcal{L}$$ 出发,用链式法则逐层回传梯度 $$\partial \mathcal{L}/\partial W$$
Update: $$W \leftarrow W - \eta \cdot \partial \mathcal{L}/\partial W$$ ($$\eta$$ 为学习率)
… 重复以上三步
过程:
1. 先预测(前向传播)→ 得到结果
2. 算误差(预测 vs 真实)→ 知道错多少
3. 反向传误差(反向传播)→ 知道谁的错
4. 调整权重(梯度下降)→ 下次做得更好
就像考试:
1. 做题(前向)
2. 对答案(算误差)
3. 分析错在哪(反向)
4. 改正错误(更新权重)
批大小(batch)与学习率
| 超参数 | 含义 | 影响 |
|---|---|---|
| 学习率 η | 每步更新的步长 | 太大震荡/发散,太小收敛慢 |
| 批大小 batch | 每次估计梯度用的样本数 | 大批稳定但费内存,小批噪声大但泛化常更好 |
常见有批量梯度下降、随机梯度下降(SGD)、小批量(mini-batch)三种;小批量是工程实践主流。
核心意思:
反向传播 = 从错误中学习,把误差传回去,调整权重
举个例子:
训练一个识别数字的网络:
第一步:前向传播
输入:手写数字"7"的图片
预测:[0.1, 0.2, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]
真实:[0, 0, 0, 0, 0, 0, 0, 1, 0, 0](第7个位置是1)
第二步:计算误差
损失 = -log(0.1) = 2.3(预测越准,损失越小)
第三步:反向传播
从输出层开始,计算每个权重对误差的贡献
用链式法则:∂Loss/∂W = ∂Loss/∂a × ∂a/∂z × ∂z/∂W
第四步:更新权重
W_new = W_old - learning_rate × ∂Loss/∂W
比如:W_old = 0.5, learning_rate = 0.01, ∂Loss/∂W = 0.3
W_new = 0.5 - 0.01 × 0.3 = 0.497
生活类比:
就像考试:
1. 做题(前向传播)
2. 对答案(算误差)
3. 分析错在哪(反向传播)
4. 改正错误(更新权重)
为什么要反向传播?
因为需要知道"谁的错",才能有针对性地改正。
核心意思:
梯度下降 = 沿着"下坡方向"走,让损失越来越小
举个例子:
损失函数:L(w) = (w - 3)²
目标:找到w使L最小(显然是w=3)
初始:w = 0
学习率:η = 0.1
迭代过程:
第1步:
梯度:dL/dw = 2(w-3) = 2(0-3) = -6
更新:w = w - η × 梯度 = 0 - 0.1×(-6) = 0.6
损失:L = (0.6-3)² = 5.76
第2步:
梯度:dL/dw = 2(0.6-3) = -4.8
更新:w = 0.6 - 0.1×(-4.8) = 1.08
损失:L = (1.08-3)² = 3.69
第3步:
梯度:dL/dw = 2(1.08-3) = -3.84
更新:w = 1.08 - 0.1×(-3.84) = 1.464
损失:L = (1.464-3)² = 2.36
...继续迭代...
最终:w ≈ 3,损失 ≈ 0
学习率的影响:
学习率太大:震荡,可能发散
学习率太小:收敛慢,费时间
学习率合适:稳定收敛
生活类比:
- 梯度下降:像在山上找最低点
- 梯度:告诉你哪个方向是"下坡"
- 学习率:告诉你每步走多远
- 损失函数:告诉你当前有多高
7归一化层
归一化层基于一群神经元的取值,把激活值压缩到更优的数值范围,有利于训练稳定与加速收敛。
| 类型 | 归一化对象 |
|---|---|
| 数据归一化 (Data Norm) | 每个变量在数据集上变成零均值、单位方差 |
| 批归一化 (BatchNorm) | 对激活张量的一列(同一特征跨样本)做标准化:减均值、除方差 |
| 层归一化 (LayerNorm) | 对激活张量的一行(同一样本跨特征)做标准化 |
8过拟合与正则化
过拟合:模型在训练集表现好,但在未见数据(测试集 / OOD)表现差——把噪声也"背"了下来。常用对策:
权重正则化
L2 / L1 惩罚大权重,偏好更简单的模型(奥卡姆剃刀)。
Dropout
训练时随机丢弃部分神经元,减少共适应、增强泛化。
提前停止
验证集误差回升时停止训练,避免继续拟合噪声。
⭐重点例题
Forward :逐层算激活,得到预测 $$\hat{y}$$ 与损失 $$\mathcal{L}$$
Backward:从 $$\mathcal{L}$$ 出发,链式法则逐层求 $$\partial \mathcal{L}/\partial W$$
Update :$$W \leftarrow W - \eta \cdot \partial \mathcal{L}/\partial W$$($$\eta$$ 学习率)
关键点:反向传播是链式求导的高效实现;梯度下降沿负梯度方向更新使损失下降。
🎯自测(点击展开)
没有激活函数(非线性)的多层网络等价于什么?
Sigmoid 的主要缺点是什么?
经验风险与期望风险是什么关系?
学习率太大或太小分别会怎样?
BatchNorm 和 LayerNorm 的区别?
列举两种缓解过拟合的方法。
📝强化题库
选择题点选即时判分;填空题输入后"检查"或"显示答案"。